4.5. Inferencia básica#
Importante
Para esta libreta utilizaremos la libería scipy, que ya debería estar instalada en en entorno local, pero si no, puedes utilizar uv add scipy en tu terminal. La librería ya está preinstalada en colab.
En esta librería continuaremos trabajando con la el dataset palmer penguins y realizaremos algunas de las pruebas inferenciales más comunes.
Antes de iniciar, revisa la documentación de scipy aquí
4.5.1. Librerías#
import pandas as pd
import scipy.stats as stats
import matplotlib.pyplot as plt
import seaborn as sns
print('librerías cargadas')
librerías cargadas
Similar a matplotlib importamos un «submódulo» de scipy que se llama stats.
4.5.2. Cargar datos#
url = 'https://raw.githubusercontent.com/raphaelvallat/pingouin/refs/heads/main/src/pingouin/datasets/penguins.csv'
df = pd.read_csv(url)
df.head()
| species | island | bill_length_mm | bill_depth_mm | flipper_length_mm | body_mass_g | sex | |
|---|---|---|---|---|---|---|---|
| 0 | Adelie | Biscoe | 37.8 | 18.3 | 174.0 | 3400.0 | female |
| 1 | Adelie | Biscoe | 37.7 | 18.7 | 180.0 | 3600.0 | male |
| 2 | Adelie | Biscoe | 35.9 | 19.2 | 189.0 | 3800.0 | female |
| 3 | Adelie | Biscoe | 38.2 | 18.1 | 185.0 | 3950.0 | male |
| 4 | Adelie | Biscoe | 38.8 | 17.2 | 180.0 | 3800.0 | male |
4.5.3. Pruebas de bondad de ajuste#
Pese al gran debate que existe en torno a este tipo de pruebas, son muy utilizadas así que veremos cómo hacerlas.
Lo que se prueba es la hipótesis nula de que los datos provienen de una determinada distribución paramétrica, principalmente la normal.
Veremos tres pruebas:
Shapiro-Wilk (SW)
Kolmogórov-Smirnov (KS)
Anderson-Darling (AD)
Scipy implementa también otras, pero no las veremos en el curso.
Seleccionaremos una variable específica (body_mass_g) para las pruebas y acompañaremos el análisis con un histograma con densidad.
4.5.3.1. Visualización de distribución#
sns.displot(
data=df,
x='body_mass_g',
kde=True,
)
plt.title('Distribución de peso')
Text(0.5, 1.0, 'Distribución de peso')
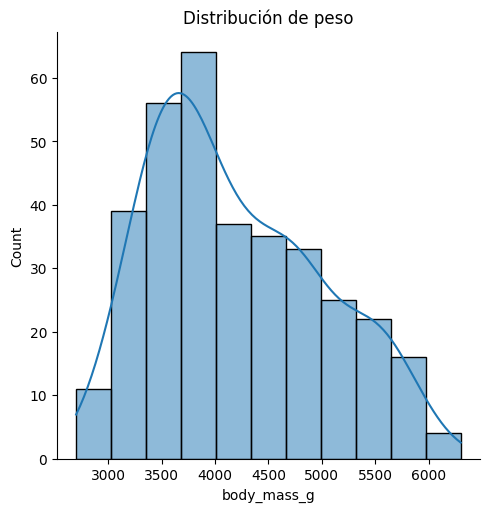
Podemos ver una distribución con asimetría positiva, probablemente porque tenemos tres subpoblaciones, podemos separar cada población, agregando una línea o dos más.
g = sns.displot(
data=df,
x='body_mass_g',
kde=True,
col='species',
hue='species', # solo para el color
)
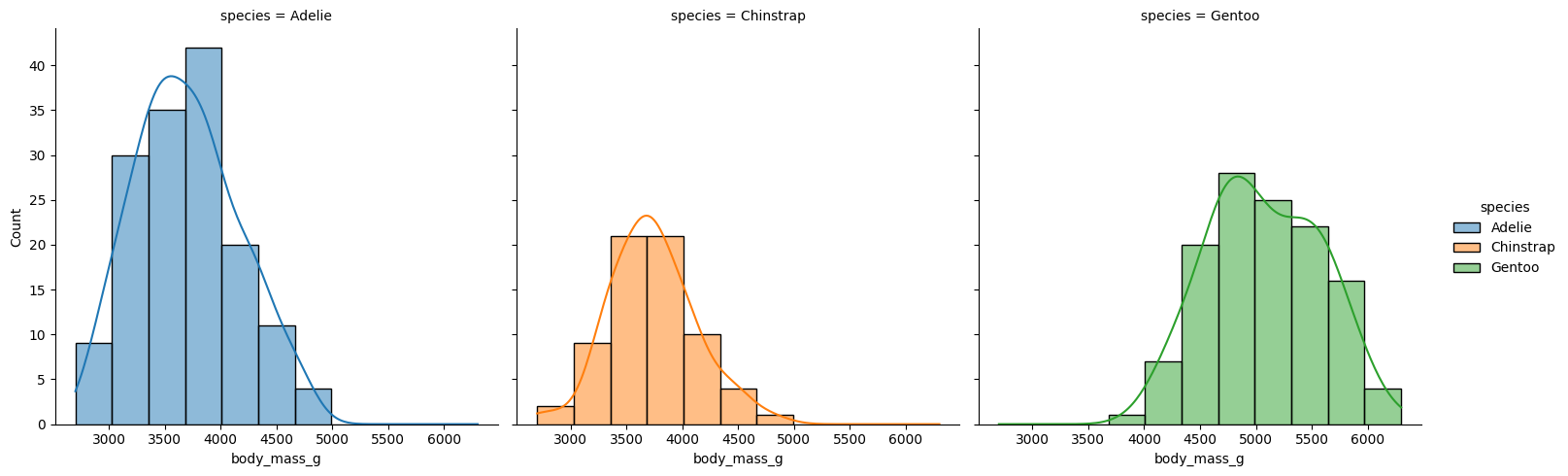
Separando las subpoblaciones podemos ver distribuciones aproximadamente normales.
4.5.3.2. Shapiro-Wilk#
peso = df['body_mass_g'].dropna() # quitamos los pingüinos con datos faltantes
stats.shapiro(peso)
ShapiroResult(statistic=np.float64(0.9592111774906512), pvalue=np.float64(3.6790392409769466e-08))
La prueba de shapiro para toda la población arroja una p menor a 0.05 que no permite rechazar la hipótesis de que los datos no son normales. Repitamos la prueba por cada subpoblación.
for especie in df['species'].unique(): # elejimos los valores únicos
filtro = df['species'] == especie
peso = df[filtro]['body_mass_g'].dropna()
print(especie, 'n=', len(peso)) # queremos también saber la n
resultado = stats.shapiro(peso)
print(resultado)
Adelie n= 151
ShapiroResult(statistic=np.float64(0.9807078507062779), pvalue=np.float64(0.03239702501304091))
Chinstrap n= 68
ShapiroResult(statistic=np.float64(0.984493761674102), pvalue=np.float64(0.5605082387697975))
Gentoo n= 123
ShapiroResult(statistic=np.float64(0.9859276066609362), pvalue=np.float64(0.23361648888961845))
Vemos que solo en la subpoblación de pingüinos Adelie, la prueba de Shapiro indica normalidad.
Probemos ahora el mismo procedimiento con la prueba de KS.
4.5.3.3. Kolmogórov-Smirnov#
En la prueba de KS probamos una hipótesis general, pero la prueba corrobora la bondad de ajuste a cualquier tipo de distribución que debemos especificar.
Scipy contiene prácticamente todas las distribuciones paramétricas habituales, la normal está en stats.norm.
Nota
La prueba de KS requiere fijar los parámetros de la distribución teórica. Es decir, si asumimos que el peso se distribuye como una normal, debemos indicar cuál es la media (\(\mu\)) y la desviación estándar (\(\sigma\)) de esa normal. Como no conocemos los parámetros verdaderos de la población, los estimamos a partir de la muestra utilizando stats.norm.fit, que devuelve los estimadores de máxima verosimilitud.
Advertencia
Importante: KS no es válida si se usan los mismos datos para estimar los parámetros y para probar el ajuste (como estamos haciendo aquí). Esto puede inflar el error tipo I, y por eso no se recomienda usar KS con parámetros estimados directamente de la muestra. Para este caso, se prefiere Anderson-Darling o Shapiro-Wilk.
Aun así, KS sigue siendo útil para ilustrar el concepto de bondad de ajuste si se aclaran sus limitaciones.
peso = df['body_mass_g'].dropna()
media, desviación = stats.norm.fit(peso)
# fit regresa la media y la desviación para la población
# No usamos el estimador de la muestra (con corrección de Bessel)
# porque la prueba es sobre la distribución, no la muestra.
resultado = stats.kstest(peso, cdf=stats.norm.cdf, args=(media, desviación))
print(resultado)
KstestResult(statistic=np.float64(0.1043424927687811), pvalue=np.float64(0.0010734945916456773), statistic_location=np.float64(3800.0), statistic_sign=np.int8(1))
Nuevamente tenemos un resultado no normal, separemos por especie.
for especie in df['species'].unique(): # elejimos los valores únicos
filtro = df['species'] == especie
peso = df[filtro]['body_mass_g'].dropna()
media, desviación = stats.norm.fit(peso)
# Prueba KS contra una N(loc, scale)
resultado = stats.kstest(peso, cdf=stats.norm.cdf, args=(media, desviación))
print(especie, 'n=', len(peso))
print(resultado)
Adelie n= 151
KstestResult(statistic=np.float64(0.07287416687604759), pvalue=np.float64(0.3806981713520229), statistic_location=np.float64(3550.0), statistic_sign=np.int8(1))
Chinstrap n= 68
KstestResult(statistic=np.float64(0.09215056172326219), pvalue=np.float64(0.5784408198748531), statistic_location=np.float64(3800.0), statistic_sign=np.int8(1))
Gentoo n= 123
KstestResult(statistic=np.float64(0.0690930363707869), pvalue=np.float64(0.5757241398765987), statistic_location=np.float64(5500.0), statistic_sign=np.int8(-1))
Esta vez vemos que las tres subpoblaciones son normales.
Veamos ahora la prueba de Anderson Darling:
4.5.3.4. Anderson Darling#
Es una prueba derivada de KS pero específicamente para la distribución normal.
Probemos nuevamente para toda la muestra.
peso = df['body_mass_g'].dropna()
stats.anderson(peso)
AndersonResult(statistic=np.float64(4.543039287872375), critical_values=array([0.569, 0.649, 0.778, 0.908, 1.08 ]), significance_level=array([15. , 10. , 5. , 2.5, 1. ]), fit_result= params: FitParams(loc=np.float64(4201.754385964912), scale=np.float64(801.9545356980955))
success: True
message: '`anderson` successfully fit the distribution to the data.')
La prueba nos dice que el estadístico es 4.54 y para una significancia del 5% (p < 0.05) el punto de corte sería 0.778, por lo cual no podemos rechazar la hipótesis de que los datos no son normales.
4.5.3.4.1. Ejercicio#
Ejecuta la prueba de AD para cada una de las subpoblaciones.
4.5.4. Resultados con Scipy#
La gran mayoría de las pruebas estadísticas con scipy devuelven un objeto que se llama NamedTuple. Estos objetos son muy fáciles de utilizar y nos ayudan a extraer los valores individuales de cada resultado. Para saber qué valores contine un resultado, es necesario ver su documentación. Pongamos de ejemplo la prueba de SW nuevamente.
peso = df['body_mass_g'].dropna()
resultado = stats.shapiro(peso)
print('Valor p:', resultado.pvalue)
print('Estadístico:', resultado.statistic)
Valor p: 3.6790392409769466e-08
Estadístico: 0.9592111774906512
Esto nos ayuda a generar reportes automatizados de la siguiente manera. Seleccionaremos solo la población de Chinstrap.
chinstrap = df[df['species'] == 'Chinstrap']
for var in chinstrap.select_dtypes(float): # seleccionamos las numéricas
datos = chinstrap[var].dropna()
resultado = stats.shapiro(datos)
p = resultado.pvalue
normal = "sí es normal" if p > 0.05 else "no es normal"
print(f'La variable "{var}" {normal}, p={p:.4f}')
La variable "bill_length_mm" sí es normal, p=0.1941
La variable "bill_depth_mm" sí es normal, p=0.1418
La variable "flipper_length_mm" sí es normal, p=0.8106
La variable "body_mass_g" sí es normal, p=0.5605
4.5.4.1. Ejercicio#
Replícalo para las demás especies.
4.5.5. Pruebas de asociación bivariadas#
Veremos ahora cómo realizar pruebas de asociación, usaremos solo \(X^2\) y la exacta de fisher.
4.5.5.1. Chi cuadrada#
Primero vamos cómo generar tablas cruzadas con pandas, para ello, seleccionaremos dos variables, species y island.
matriz = pd.crosstab(
df['island'], # filas
df['species'], # columnas
)
matriz
| species | Adelie | Chinstrap | Gentoo |
|---|---|---|---|
| island | |||
| Biscoe | 44 | 0 | 124 |
| Dream | 56 | 68 | 0 |
| Torgersen | 52 | 0 | 0 |
Esto nos genera una tabla con la cuenta de pingüinos que cumplen con cada valor de ambas variables. Vemos que los Adelie viven en las tres islas, mientras que los Chinstrap y Gentoo solo viven en Dream y Biscoe respectivamente.
Guardamos además la tabla en la variable matriz.
Ahora ejecutemos la \(X^2\).
stats.chi2_contingency(matriz)
Chi2ContingencyResult(statistic=np.float64(299.55032743148195), pvalue=np.float64(1.354573829719252e-63), dof=4, expected_freq=array([[74.23255814, 33.20930233, 60.55813953],
[54.79069767, 24.51162791, 44.69767442],
[22.97674419, 10.27906977, 18.74418605]]))
Esta corresponde a la chi cuadrada de independencia y vemos que el valor p es menor a 0.05. También podemos ver que en las frecuencias esperadas no hay celdas con menos de 5 valores y el tamaño de muestra es apropiado.
Veamos ahora la prueba de fisher.
4.5.5.2. Exacta de Fisher#
Para esta prueba requerimos una tabla 2x2, así que utilizaremos la variable sex y crearemos una nueva variable, peso_bajo_media en la cual veremos si el peso de un pingüino está por debajo de la media.
peso_bajo_media = df['body_mass_g'] < df['body_mass_g'].mean()
matriz = pd.crosstab(
df['sex'],
peso_bajo_media
)
matriz
| body_mass_g | False | True |
|---|---|---|
| sex | ||
| female | 53 | 112 |
| male | 92 | 76 |
Vemos ahora que tenemos una tabla 2x2, con nuestra variable calculada. Ahora ejecutemos la prueba de fisher.
stats.fisher_exact(matriz)
SignificanceResult(statistic=np.float64(0.390916149068323), pvalue=np.float64(4.046749537813585e-05))
Podemos ver que existe una asociación entre el sexo y tener peso debajo de la media. Ajustemos el análisis para ver si es el sexo female el asociado.
peso_bajo_media = df['body_mass_g'] < df['body_mass_g'].mean()
female = df['sex'] == 'female'
matriz = pd.crosstab(
female,
peso_bajo_media
)
matriz
| body_mass_g | False | True |
|---|---|---|
| sex | ||
| False | 98 | 81 |
| True | 53 | 112 |
Algo raro pasó, las cuentas no son iguales, y esto se debe a que en el arreglo de datos hay faltantes, para poder analizar bien esta asociación necesitamos solo datos completos, lo haremos de la siguiente manera.
datos_completos = df.dropna(subset=['sex', 'body_mass_g'])
# quita las filas que en las que falte cualquiera de las
# dos variables
peso_bajo_media = datos_completos['body_mass_g'] < datos_completos['body_mass_g'].mean()
female = datos_completos['sex'] == 'female'
matriz = pd.crosstab(
female,
peso_bajo_media
)
matriz
| body_mass_g | False | True |
|---|---|---|
| sex | ||
| False | 92 | 76 |
| True | 53 | 112 |
Esta vez las cuentas se ven bien, hagamos nuevamente la prueba.
stats.fisher_exact(matriz)
SignificanceResult(statistic=np.float64(2.558093346573982), pvalue=np.float64(4.046749537813585e-05))
Y generemos el OR
stats.contingency.odds_ratio(matriz, kind='sample')
OddsRatioResult(statistic=2.558093346573982)
Vemos que los pingüinos hembra tienen 2.5 veces más odds de estar por debajo del peso medio, lo cual podría estar relacionado con dimorfismo sexual.
4.5.5.3. Ejercicio#
Analiza el arreglo de datos y realiza otras comparaciones de asociación.
4.5.6. Pruebas AB#
Las pruebas AB básicamente comparan dos series de datos y podemos pensarlas como un contraste entre una variable categórica (grupo) y una cuantitativa. Entre las pruebas AB más utilizadas están las pruebas t y las versiones no paramétricas basadas en rango como la U de Mann Whitney. Veamos cómo realizarlas.
4.5.6.1. T de Student#
Pleanteemos la siguiente hipótesis:
\(H_1: Peso_{hembras} \ne Peso_{machos}\)
Utilizaremos las variables de la sección previa.
datos_completos.head()
| species | island | bill_length_mm | bill_depth_mm | flipper_length_mm | body_mass_g | sex | |
|---|---|---|---|---|---|---|---|
| 0 | Adelie | Biscoe | 37.8 | 18.3 | 174.0 | 3400.0 | female |
| 1 | Adelie | Biscoe | 37.7 | 18.7 | 180.0 | 3600.0 | male |
| 2 | Adelie | Biscoe | 35.9 | 19.2 | 189.0 | 3800.0 | female |
| 3 | Adelie | Biscoe | 38.2 | 18.1 | 185.0 | 3950.0 | male |
| 4 | Adelie | Biscoe | 38.8 | 17.2 | 180.0 | 3800.0 | male |
female.head()
0 True
1 False
2 True
3 False
4 False
Name: sex, dtype: bool
Como female es una serie de datos booleanos, podemos usarla como filtro, para separar los valores de machos y hembras.
peso = datos_completos['body_mass_g']
peso_hembras = peso[female]
peso_machos = peso[~female] # ~ es el operador "not"
# es decir "not female"
# ahora hacemos la prueba T
stats.ttest_ind( # ind es independientes
peso_hembras, peso_machos
)
TtestResult(statistic=np.float64(-8.541720337994516), pvalue=np.float64(4.897246751596224e-16), df=np.float64(331.0))
Vemos que el valor p es muy inferior a 0.05, lo cual corrobora nuestra hipótesis.
Existe una variante de la prueba t que no asume varianzas iguales, la prueba t de Welch, veamos cómo aplicarla ahora.
stats.ttest_ind( # ind es independientes
peso_hembras, peso_machos,
equal_var=False, # no asumimos varianzas iguales
)
TtestResult(statistic=np.float64(-8.554537231165762), pvalue=np.float64(4.793891255051492e-16), df=np.float64(323.89588102864843))
En este caso el resultado no se modifica gran cosa.
4.5.6.2. U de Mann Whitney#
Si quisieramos realizar la prueba no paramétrica de rangos de U de Mann Whiney, lo haríamos de la siguiente forma.
stats.mannwhitneyu(peso_hembras, peso_machos,)
MannwhitneyuResult(statistic=np.float64(6874.5), pvalue=np.float64(1.8133343032461053e-15))
4.5.7. Correlación#
Existen varias pruebas de correlación pero las tres principalmente utilizadas son r de Pearson, rho de Spearman y Tau de Kendall, veamos cómo ejecutarlas.
Para esto, seleccionaremos dos variables cuantitativas, en este ejemplo flipper_length_mm y bill_length_mm.
Primero separemos las series de interés.
datos_completos = df.dropna(subset=['flipper_length_mm', 'bill_length_mm'])
flippers = datos_completos['flipper_length_mm']
bill = datos_completos['bill_length_mm']
print('Datos separados correctamente')
Datos separados correctamente
Ahora las correlaciones.
4.5.7.1. Pearson#
stats.pearsonr(flippers, bill)
PearsonRResult(statistic=np.float64(0.656181340746428), pvalue=np.float64(1.7439736176203663e-43))
4.5.7.2. Spearman#
stats.spearmanr(flippers, bill)
SignificanceResult(statistic=np.float64(0.6727719416255544), pvalue=np.float64(2.0669356276079494e-46))
4.5.7.3. Kendall#
stats.kendalltau(flippers, bill)
SignificanceResult(statistic=np.float64(0.48334544176274524), pvalue=np.float64(1.7471887323081624e-39))
En los tres casos encontramos una relación directa moderada y estadísticamente significativa entre las variables. Visualicémoslo.
4.5.7.4. Visualización#
sns.regplot(
x=flippers,
y=bill,
)
<Axes: xlabel='flipper_length_mm', ylabel='bill_length_mm'>
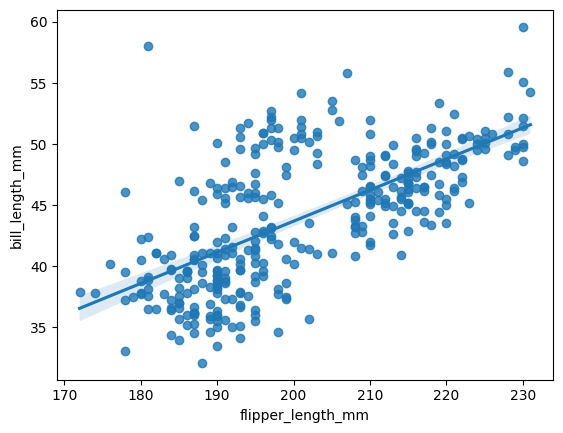
4.5.7.5. Ejercicio#
Genera una visualización y las tres correlaciones para las tres diferentes especies.